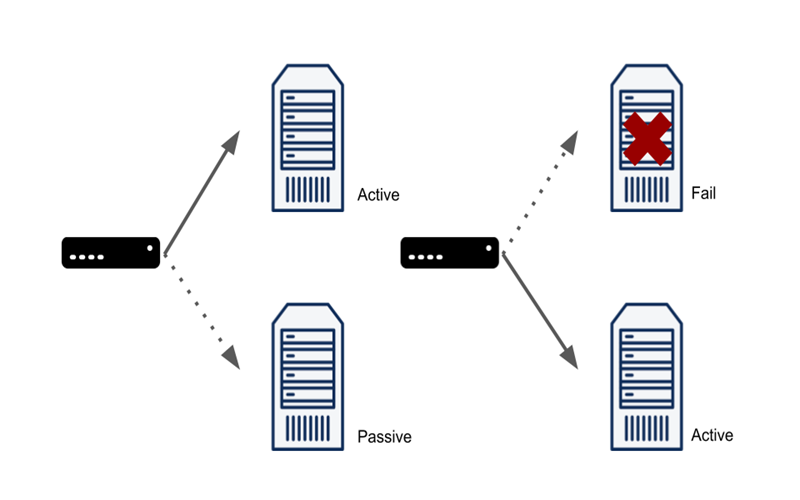
1. Mục tiêu của đồng bộ và failover
Đồng bộ BV1 → BV2 và failover không nhằm thay thế backup, mà phục vụ các mục tiêu sau:
Giảm thời gian gián đoạn dịch vụ nội bộ
Đảm bảo BV2 có thể online nhanh khi BV1 gặp sự cố
Cho phép xử lý sự cố BV1 có kiểm soát, không hoảng loạn
Nguyên tắc cốt lõi:
Replication để sẵn sàng, backup để khôi phục.
2. Phân vai rõ ràng giữa BV1 và BV2
2.1. BV1 – Primary
Chạy dịch vụ chính
Phát sinh dữ liệu
Là nguồn duy nhất được ghi
2.2. BV2 – Standby
Không phục vụ ghi dữ liệu
Nhận đồng bộ từ BV1
Chỉ online khi:
BV1 lỗi
Có quyết định failover
BV2 không được chạy song song với BV1 ở chế độ active-active.
3. Phạm vi và đối tượng đồng bộ
3.1. Những gì ĐƯỢC đồng bộ
Code website/webapp
Files cần thiết để vận hành
Dữ liệu đã được xác định phục vụ dịch vụ
3.2. Những gì KHÔNG đồng bộ
Thư mục backup
File tạm
Log hệ thống
Cache
Nguyên tắc:
Không để lỗi ở BV1 nhân bản sang BV2 một cách mù quáng.
4. Cơ chế đồng bộ BV1 → BV2
4.1. Hình thức đồng bộ
Sử dụng:
rsyncreplication
Kết nối:
SSH key riêng
Chạy:
Theo lịch (cron)
Hoặc thủ công khi cần
4.2. Kiểm soát tính toàn vẹn
Sử dụng:
Checksum
Log rõ:
File thay đổi
Dung lượng
Thời gian
4.3. Đồng bộ có kiểm soát
Không dùng
--deletemặc địnhChỉ xóa khi:
Đã kiểm tra
Có snapshot backup
5. Tránh split-brain – nguyên tắc sống còn
Split-brain xảy ra khi:
BV1 và BV2 cùng ghi dữ liệu
Không kiểm soát vai trò primary/standby
5.1. Biện pháp bắt buộc
Chỉ PRX điều phối traffic
Không expose trực tiếp BV1/BV2 ra Internet
Có biến cấu hình:
PRIMARY=true/false
Thực tế có file cấu hình nginx ở snippets/server-backed,conf --> chỉ đổi IP BV1 hay BV2 khi cần BV1 hỏng. Sau khi đã ngắt replication và dừng rsync (xem bước 5.2).
5.2. Quy trình kiểm soát
Trước failover:
Đảm bảo BV1 offline hoàn toàn
Sau failover:
Khóa ghi trên BV1 (nếu còn sống)
Chỉ BV2 được ghi
6. Kịch bản failover BV1 → BV2
6.1. Điều kiện kích hoạt failover
BV1:
Không truy cập được
Lỗi hệ điều hành
Lỗi storage
Tóm lại chủ yếu là lỗi phần cứng mới có thể làm BV1 fail!
Dự kiến downtime > ngưỡng cho phép
6.2. Các bước failover chuẩn
Xác nhận sự cố BV1
Ping / SSH / service check
Ngắt BV1 khỏi hệ thống
Stop service
Hoặc cách ly mạng
Chuyển routing tại PRX
Trỏ toàn bộ traffic sang BV2
Kích hoạt dịch vụ trên BV2
Start web/service
Kiểm tra dịch vụ
Truy cập thử
Kiểm tra chức năng chính
6.3. Thời gian mục tiêu
RTO nội bộ:
15–30 phút (thực tế)
Không cần zero-downtime
7. Failback (BV2 → BV1) – điểm hay bị bỏ qua
7.1. Nguyên tắc
Không failback vội
Phải xác định:
Dữ liệu nào phát sinh trên BV2
Cách nhập lại BV1
7.2. Quy trình tổng quát
Sửa chữa BV1
Đồng bộ dữ liệu từ BV2 → BV1 (có chọn lọc)
Test BV1
Chuyển routing lại tại PRX
Đưa BV2 về standby
Hoặc có thể đổi luôn vai trò của BV1 và BV2 nếu không có gì đặc biệt.
Cá nhân mình đang chạy model AI, một số app nặng trên BV2. Nên chắc chắn sẽ quay lại BV1 sau khi đã khắc phục BV1.
8. Quan hệ giữa failover và backup
| Tình huống | Failover | Backup |
|---|---|---|
| BV1 chết nhanh | ✔ | ✖ |
| Lỗi logic dữ liệu | ✖ | ✔ |
| Ransomware | ✖ | ✔ |
| Thảm họa | ✖ | ✔ |
Failover:
Giải quyết gián đoạn
Backup:
Giải quyết mất dữ liệu
9. Checklist failover rút gọn
BV1 offline hoàn toàn
PRX trỏ đúng BV2
(Có thể cần test xem đã online được các web hay không. Có thể cần fix các lỗi vặt nếu như trước đó chưa test cẩn thận)
BV2 service up
Kiểm tra dữ liệu
Ghi log sự cố
Tổng kết
Mô hình BV1 → BV2 của mình:
Đơn giản
Dễ vận hành
Phù hợp đội CNTT bệnh viện
Nhưng chỉ an toàn khi:
Phân vai rõ
Failover có quy trình
Backup độc lập vẫn tồn tại
Phương án failover này có thời gian downtime cũng như số giây dữ liệu bị mất chấp nhận được trong môi trường bệnh viện.
- Đăng nhập để gửi ý kiến
