
Xử lý tài liệu bằng AI đang làm thay đổi việc quản lý nội dung trong Drupal. Thông qua việc tích hợp với AI Automators, Unstructured.io và các mô hình GPT, các nhóm biên tập có thể tự động hóa các tác vụ tẻ nhạt như trích xuất siêu dữ liệu, đối sánh phân loại và tạo tóm tắt. Nghiên cứu trường hợp này cho thấy cách BetterRegulation triển khai xử lý tài liệu bằng AI trên nền tảng Drupal 11 của họ, đạt được độ chính xác hơn 95% và tiết kiệm 50% thời gian biên tập.
Giới thiệu: Tại sao nên sử dụng xử lý tài liệu bằng AI trong Drupal?
Drupal từ lâu đã là một công cụ mạnh mẽ trong quản lý nội dung, đặc biệt là đối với nội dung phức tạp và có cấu trúc. Nhưng khi khối lượng nội dung tăng lên và kỳ vọng của người dùng thay đổi, việc xử lý tài liệu thủ công trở thành một nút thắt cổ chai.
Xử lý tài liệu bằng AI tự động hóa việc trích xuất, phân loại và sắp xếp thông tin từ tài liệu trên quy mô lớn. AI kết hợp với Drupal giúp điều này trở nên khả thi đối với các quy trình quản lý nội dung. Hãy tưởng tượng:
- Các tài liệu được tự động phân loại dựa trên 15 trường siêu dữ liệu với độ chính xác 95%.
- Tóm tắt được tạo tự động cho mỗi nội dung.
- Các tham chiếu thực thể được tạo ra một cách thông minh dựa trên sự hiểu biết về ngữ nghĩa.
- Các nhóm biên tập được giải phóng khỏi công việc nhập liệu tẻ nhạt để tập trung vào chiến lược.
Đây không phải là điều viễn tưởng mà là hiện thực trong sản xuất. BetterRegulation, một nền tảng tuân thủ pháp luật chạy trên Drupal 11, đã bổ sung khả năng trí tuệ nhân tạo (AI) vào hệ thống hiện có của họ và hiện xử lý hơn 200 tài liệu pháp lý phức tạp mỗi tháng, đạt được những thành tựu sau:
- Tiết kiệm 50% thời gian xử lý tài liệu
- Giải phóng 1 nhân viên toàn thời gian (FTE) để tập trung vào công việc có giá trị cao hơn.
- Độ chính xác >95% trong phân loại tự động
- Lợi tức đầu tư dưới 12 tháng
Bài viết này chia sẻ kiến trúc kỹ thuật, các quyết định quan trọng và bài học kinh nghiệm từ một dự án thực tế xử lý hơn 200 tài liệu pháp lý mỗi tháng.
Những hiểu biết quan trọng bạn sẽ thu được:
- Các quyết định về kiến trúc cho xử lý tài liệu tự động: tại sao nên chọn AI Automators, Unstructured.io và GPT-4o-mini.
- Làm thế nào để đạt được độ chính xác trên 95% trong việc đối sánh phân loại tự động.
- Các chiến lược tối ưu hóa chi phí thực tế (tiết kiệm hơn 2.000 bảng Anh/năm).
- Những thách thức và giải pháp trong sản xuất (cơ chế trì hoãn 15 phút, giới hạn số lượng token).
- Khi nào nên sử dụng công cụ tự động hóa AI so với mã lập trình tùy chỉnh cho việc tự động hóa tài liệu?
Đối tượng phù hợp: Các trưởng nhóm kỹ thuật và nhà phát triển đang đánh giá việc tích hợp xử lý tài liệu bằng AI cho các nền tảng Drupal hiện có.
Bối cảnh dự án: Xử lý tài liệu bằng AI giải quyết vấn đề gì?
BetterRegulation đã có một nền tảng Drupal 11 hoàn thiện, quản lý hàng nghìn tài liệu pháp lý. Thách thức đặt ra là tích hợp khả năng xử lý tài liệu bằng trí tuệ nhân tạo vào quy trình làm việc hiện có mà không làm gián đoạn công việc của người biên tập hoặc yêu cầu xây dựng lại hoàn toàn.
Mục tiêu rất đơn giản nhưng đầy tham vọng: tự động hóa quá trình xử lý tài liệu bằng trí tuệ nhân tạo để đọc các tệp PDF, trích xuất siêu dữ liệu, đối khớp phân loại và tạo bản tóm tắt — trong khi các biên tập viên tập trung vào kiểm soát chất lượng và tuyển chọn nội dung chiến lược.
Hai tính năng chính đã được phát triển:
1. Tự động điền các trường thông tin tài liệu (Loại nội dung "Tìm hiểu cách thức") - tải lên tệp PDF, nhấp vào "Tạo bằng AI" và xem hơn 15 trường thông tin được tự động điền với loại tài liệu, tổ chức, năm, tham chiếu luật pháp, v.v. Quá trình xử lý diễn ra trong thời gian thực (1-2 phút) để người biên tập có thể xem xét và điều chỉnh ngay lập tức các trường đã được điền.
2. Bản tóm tắt do AI tạo ra (Nội dung Tư vấn chung, Trạm, Kiến thức chuyên môn) - tự động tạo ra ba loại bản tóm tắt:
- Tóm tắt chi tiết (~200 từ) - tổng quan toàn diện.
- Tóm tắt ngắn gọn (~50 từ) - bản tóm lược một đoạn văn.
- Tóm tắt các nghĩa vụ - trích dẫn các nghĩa vụ pháp lý và yêu cầu quy định.
Quá trình tạo bản tóm tắt chạy ngầm với độ trễ 15 phút để tránh xử lý lại trong quá trình chỉnh sửa nhanh.
Việc triển khai cần phải như sau:
- Không gây gián đoạn: làm việc trong phạm vi các loại nội dung và quy trình hiện có.
- Có thể cấu hình: cho phép cập nhật lời nhắc và phân loại mà không cần triển khai mã.
- Đáng tin cậy: xử lý tốt các trường hợp đặc biệt như tài liệu dài 350 trang và thuật ngữ pháp lý phức tạp.
- Hiệu quả về chi phí: xử lý hơn 200 tài liệu mỗi tháng mà không vượt quá ngân sách.
Hướng dẫn này trình bày cách chúng tôi đạt được tất cả những điều này bằng cách sử dụng hệ sinh thái mô-đun AI của Drupal.
Quá trình xử lý tài liệu bằng AI trong Drupal hoạt động như thế nào?
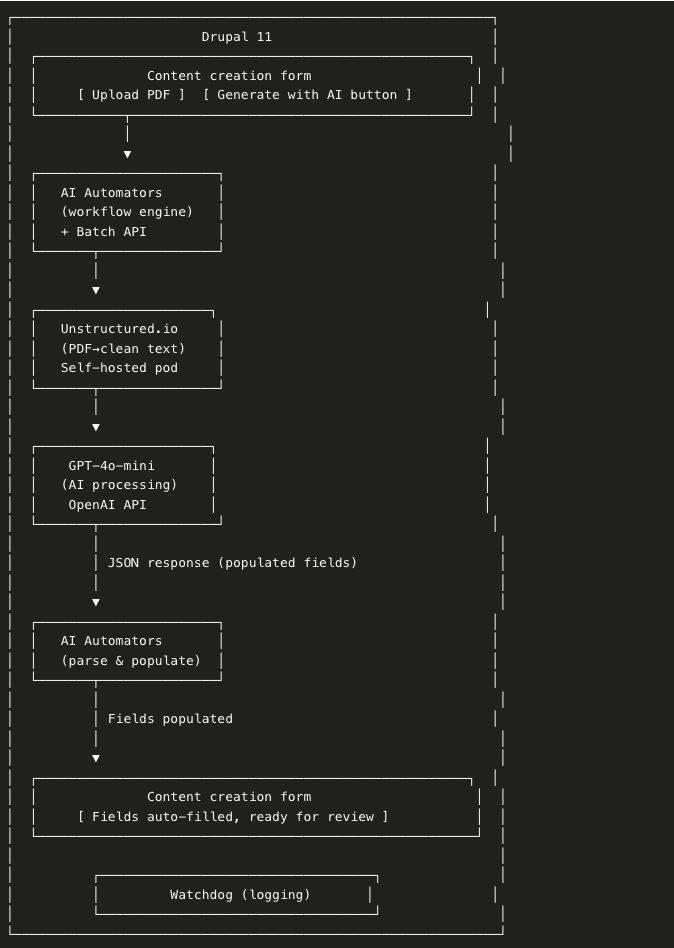
Hiểu rõ kiến trúc công nghệ là điều vô cùng quan trọng để đánh giá phương pháp này cho các dự án của riêng bạn. Việc triển khai xử lý tài liệu bằng AI của BetterRegulation kết hợp năm thành phần cốt lõi hoạt động cùng nhau để xử lý tài liệu từ khi tải lên PDF đến khi điền đầy đủ các trường nội dung.
Công nghệ nào hỗ trợ xử lý tài liệu bằng AI?
Việc triển khai trí tuệ nhân tạo của BetterRegulation sử dụng năm thành phần chính:
1. Tự động điền các trường thông tin trong tài liệu (nút "Tạo bằng AI")
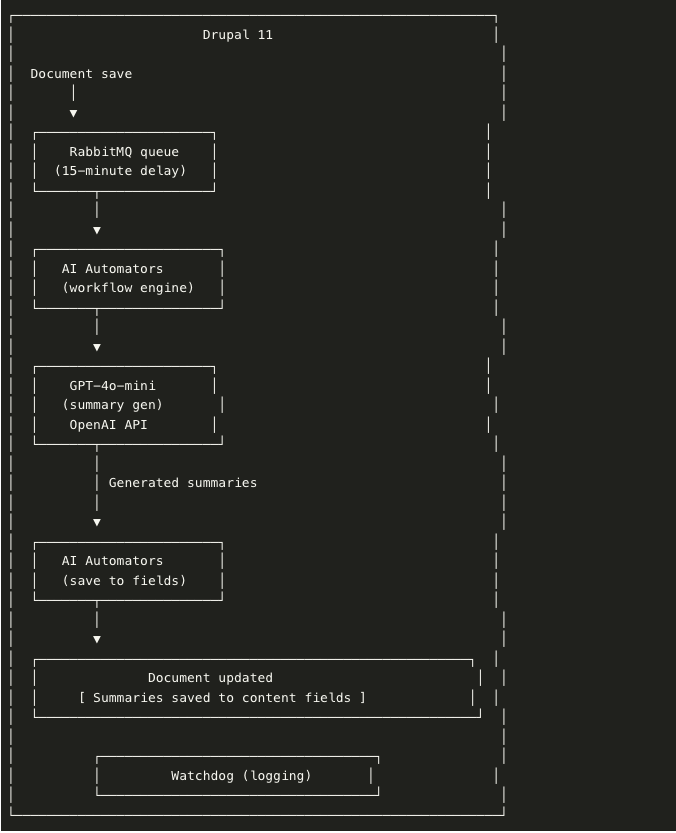
2. Bản tóm tắt do AI tạo ra (xử lý nền)
Mỗi thành phần trong quy trình xử lý tài liệu bằng AI có vai trò gì?
Drupal 11 đóng vai trò là nền tảng của toàn bộ hệ thống, cung cấp nền tảng quản lý nội dung, cấu trúc thực thể và giao diện người dùng. Nó điều phối quy trình làm việc và lưu trữ tất cả dữ liệu tài liệu, hoạt động như trung tâm nơi các biên tập viên tương tác với nội dung và nơi các kết quả được xử lý bằng AI cuối cùng được lưu trữ.
Drupal AI Automators là mô-đun đóng góp giúp kết nối Drupal với các dịch vụ AI. Thay vì xây dựng mã tích hợp tùy chỉnh, mô-đun này cung cấp phương pháp dựa trên cấu hình để định nghĩa quy trình làm việc của AI. Nó quản lý các lời nhắc, xử lý phản hồi từ nhiều nhà cung cấp AI (OpenAI, Anthropic, v.v.) và điều phối các quy trình nhiều bước thông qua giao diện quản trị trực quan. Điều này có nghĩa là việc tạo và sửa đổi quy trình làm việc của AI trở thành một nhiệm vụ cấu hình chứ không phải là một dự án phát triển. Để biết thêm ví dụ về tự động hóa AI trong Drupal, hãy xem cách tạo văn bản thay thế hình ảnh và chiến lược nội dung với các mô-đun AI .
Unstructured.io hoạt động trên một máy chủ ảo tự lưu trữ và xử lý bước đầu tiên quan trọng: chuyển đổi các tài liệu PDF lộn xộn thành văn bản có cấu trúc, rõ ràng. Nó phân tích bố cục tài liệu, bảo toàn cấu trúc, lọc bỏ các phần không cần thiết như tiêu đề và số trang, và thậm chí xử lý cả nhận dạng ký tự quang học (OCR) cho các tài liệu được quét. Kết quả là văn bản sạch được tối ưu hóa cho quá trình xử lý bằng trí tuệ nhân tạo (AI), điều cần thiết cho việc phân loại chính xác và trích xuất siêu dữ liệu.
GPT-4o-mini cung cấp sức mạnh cho phân tích AI thông qua API của OpenAI. Sau khi nhận được văn bản sạch từ Unstructured.io, nó thực hiện phân tích tài liệu, đối chiếu nội dung với hệ thống phân loại BetterRegulation, trích xuất siêu dữ liệu và tạo ra các bản tóm tắt. Mô hình trả về các phản hồi JSON có cấu trúc mà Drupal Automators có thể phân tích cú pháp và tự động điền vào các trường nội dung thích hợp.
RabbitMQ quản lý quá trình xử lý tác vụ nền, đặc biệt là việc tạo tóm tắt tốn nhiều thời gian. Khi người dùng lưu hoặc chỉnh sửa tài liệu, việc tạo tóm tắt sẽ tự động được xếp vào hàng đợi với độ trễ 15 phút. Quyết định thiết kế này xuất phát từ nhu cầu thực tế: người biên tập thường thực hiện nhiều chỉnh sửa nhanh chóng trên tài liệu, và việc xử lý tóm tắt sau mỗi lần lưu sẽ lãng phí chi phí API và thời gian xử lý. Độ trễ 15 phút cho phép người biên tập hoàn tất các thay đổi của họ trước khi quá trình xử lý AI bắt đầu. Điều này ngăn chặn việc xử lý dư thừa và cho phép hệ thống mở rộng theo chiều ngang bằng cách xử lý nhiều bản tóm tắt trên các máy chủ khác nhau.
Watchdog , hệ thống ghi nhật ký cốt lõi của Drupal, ghi lại mọi bước của quy trình. Từ việc tải lên tệp PDF đến phản hồi của AI, mọi hành động, lỗi và chỉ số hiệu suất đều được ghi lại. Việc ghi nhật ký toàn diện này đã chứng tỏ tầm quan trọng thiết yếu trong quá trình phát triển để gỡ lỗi quy trình làm việc và tiếp tục có giá trị trong việc giám sát tình trạng hoạt động của hệ thống trong môi trường sản xuất.
Tại sao nên chọn bộ công nghệ này cho việc xử lý tài liệu bằng AI?
BetterRegulation đã sử dụng Drupal 11 làm nền tảng quản lý nội dung khi họ quyết định bổ sung khả năng trí tuệ nhân tạo (AI). Thách thức đặt ra là làm thế nào để tích hợp AI vào quy trình làm việc hiện có mà không làm gián đoạn công việc của người biên tập hoặc yêu cầu những thay đổi lớn về kiến trúc hệ thống.
Việc lựa chọn AI Automators thay vì tự viết mã đã giúp tiết kiệm hàng tuần thời gian phát triển. Thay vì phải viết mã tích hợp rườm rà cho API của OpenAI, quản lý các mẫu lời nhắc và xây dựng giao diện quản trị, chúng tôi đã cấu hình quy trình làm việc thông qua giao diện đồ họa người dùng (GUI). Cách tiếp cận "cấu hình thay vì viết mã" này có nghĩa là các sửa đổi trong tương lai—như thêm các bước AI mới hoặc chuyển đổi nhà cung cấp—có thể được thực hiện mà không cần triển khai mã mới. Mô-đun này được cộng đồng duy trì, vì vậy các cải tiến và cập nhật bảo mật đến từ hệ sinh thái Drupal rộng lớn hơn.
Đối với việc xử lý PDF, Unstructured.io đã chứng tỏ vượt trội hơn so với phương pháp trích xuất trực tiếp trên mọi chỉ số quan trọng. Các thử nghiệm ban đầu với các thư viện PDF tiêu chuẩn cho thấy chất lượng trích xuất chỉ đạt 75% và tạo ra văn bản chứa đầy số trang, tiêu đề và các lỗi định dạng. Unstructured.io đạt được chất lượng 94% và tạo ra văn bản sạch, tiết kiệm được 30% chi phí cho AI. Việc tự lưu trữ dịch vụ trên cơ sở hạ tầng hiện có đã loại bỏ phí xử lý trên mỗi tài liệu, giúp dịch vụ trở nên khả thi về mặt kinh tế ngay cả với hàng nghìn tài liệu.
Việc lựa chọn GPT-4o-mini thay vì GPT-4 dựa trên yếu tố kinh tế và tính đáp ứng. Mặc dù GPT-4 có nhiều khả năng hơn, nhưng GPT-4o-mini đã chứng tỏ hoàn toàn đáp ứng được nhu cầu đối sánh phân loại và trích xuất siêu dữ liệu. Với chi phí thấp hơn 10 lần và cửa sổ ngữ cảnh 128K (đủ cho tài liệu 350 trang), nó mang lại sự cân bằng hoàn hảo giữa khả năng và giá cả phải chăng. Tốc độ xử lý nhanh hơn là một lợi thế giúp cải thiện trải nghiệm người dùng.
Để so sánh chi tiết các phương pháp tích hợp AI khác nhau, hãy đọc bài viết LangChain vs LangGraph vs Raw OpenAI: cách chọn bộ công cụ RAG của bạn .
Cách triển khai xử lý tài liệu bằng AI trong Drupal
Sau khi đã xác định được kiến trúc tổng thể, chúng ta hãy xem xét cách các thành phần này được xây dựng và cấu hình trên thực tế. Việc triển khai tập trung vào việc tận dụng các mô-đun Drupal hiện có thay vì xây dựng mã tùy chỉnh từ đầu.
Phương pháp xây dựng
Thay vì tự xây dựng mã tích hợp AI từ đầu, chúng tôi đã tận dụng mô-đun AI Automators của Drupal — một phương pháp dựa trên cấu hình giúp tiết kiệm hàng tuần thời gian phát triển và cung cấp độ tin cậy cấp doanh nghiệp ngay từ đầu.
Các thành phần cốt lõi được xây dựng
1. Dịch vụ trích xuất văn bản PDF
Chúng tôi đã tạo một dịch vụ Drupal tùy chỉnh để gửi các tệp PDF đến máy chủ Unstructured.io tự lưu trữ và nhận lại văn bản có cấu trúc, được làm sạch. Dịch vụ này lọc bỏ tiêu đề, chân trang, số trang và giữ nguyên cấu trúc tài liệu — điều cực kỳ quan trọng cho việc phân tích AI chính xác.
Quyết định quan trọng trong quá trình triển khai: Chỉ lọc các phần tử Title, NarrativeText, và ListItemtừ phản hồi của Unstructured.io. Điều này giúp loại bỏ nhiễu trong khi vẫn giữ nguyên cấu trúc logic của tài liệu.
2. Cấu hình quy trình làm việc của Automator
Sử dụng giao diện quản trị của AI Automators ( /admin/config/ai/automator_chain_types/manage/summary/automator_chain), chúng tôi đã cấu hình quy trình làm việc hai bước:
- Bước 1: Trích xuất văn bản từ PDF → lưu vào trường tạm thời
- Bước 2: Gửi văn bản + phân loại đến GPT-4o-mini → nhận phản hồi JSON
Không cần viết mã tùy chỉnh cho việc tích hợp API AI — AI Automators sẽ xử lý việc quản lý nhà cung cấp, logic thử lại và xử lý lỗi.
3. Kỹ thuật nhanh chóng để khớp phân loại
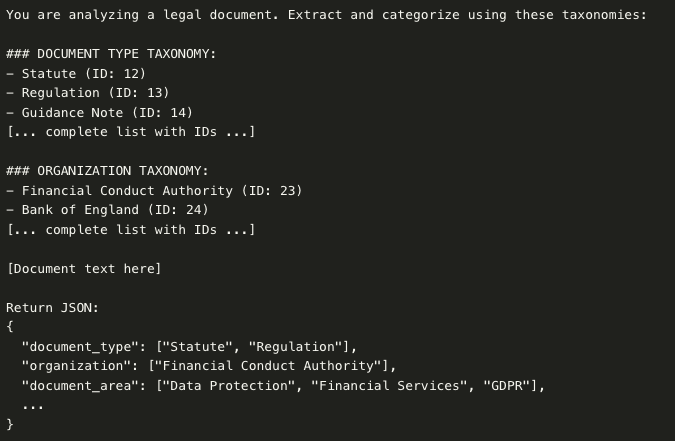
Bí quyết để đạt độ chính xác trên 95%: chèn trực tiếp danh sách phân loại đầy đủ vào câu lệnh .
Cấu trúc câu hỏi gợi ý trông như sau (prompt):
Những quyết định quan trọng:
- Tải phân loại động: Mã PHP truy vấn các phân loại của Drupal và xây dựng ngữ cảnh nhắc nhở ngay lập tức. Việc thay đổi phân loại không yêu cầu cập nhật nhắc nhở.
- Trí tuệ nhân tạo (AI) trả về tên các thuật ngữ phân loại: AI trả về tên các thuật ngữ phân loại (ví dụ:
["Data Protection", "Financial Services", "GDPR"]), chứ không phải ID. Sau đó, hệ thống thực hiện tra cứu để khớp các tên này với ID thuật ngữ trong hệ thống phân loại của Drupal. Cách tiếp cận này tận dụng khả năng hiểu ngữ nghĩa của AI trong khi vẫn duy trì tham chiếu thực thể chính xác. - Ánh xạ tên-ID: sau khi AI trả về tên thuật ngữ, hệ thống sẽ tìm kiếm trong từ vựng phân loại để tìm các thuật ngữ phù hợp và truy xuất ID của chúng. Ví dụ:
"Data Protection"→ tìm thấy ID thuật ngữ42,"Financial Services"→ tìm thấy ID thuật ngữ87,"GDPR"→ tìm thấy ID thuật ngữ156. Sau đó, tài liệu được gán một mảng các ID:[42, 87, 156]. - Đối sánh ngữ nghĩa: AI hiểu “cho vay tiêu dùng” = “Các tổ chức cho vay tín dụng tiêu dùng” ngay cả khi không có sự trùng khớp chính xác giữa các từ khóa. Phương pháp dựa trên tên cho phép AI sử dụng khả năng hiểu ngữ nghĩa của mình để đối sánh các khái niệm, trong khi hệ thống đảm bảo độ chính xác thông qua việc đối sánh chính xác tên thuật ngữ trong quá trình tra cứu phân loại.
Chi phí token: việc thêm phân loại làm tăng kích thước lời nhắc thêm khoảng 5.000 token cho mỗi yêu cầu, tốn thêm 0,03 bảng Anh cho mỗi tài liệu. Việc cải thiện độ chính xác (75% → 95%) giúp tiết kiệm hơn 12 phút chỉnh sửa thủ công cho mỗi tài liệu, mang lại lợi tức đầu tư (ROI) gấp 70 lần.
4. Nút “Tạo bằng AI”
Chúng tôi đã thêm một nút hỗ trợ AJAX vào biểu mẫu chỉnh sửa nội dung, nút này sẽ kích hoạt quy trình xử lý và điền thông tin vào các trường theo thời gian thực. Người chỉnh sửa sẽ thấy các trường trong biểu mẫu được điền tự động và có thể xem lại/điều chỉnh trước khi lưu.
Đây là một ví dụ về xử lý tài liệu bằng AI mà chúng tôi đã triển khai cho Better Regulation.
Đọc toàn bộ nghiên cứu trường hợp Phân loại tài liệu bằng AI tại đây →
Những thách thức kỹ thuật chính trong xử lý tài liệu bằng trí tuệ nhân tạo là gì?
Mỗi dự án tích hợp AI đều đối mặt với những thách thức riêng. Dưới đây là ba trở ngại kỹ thuật quan trọng nhất mà BetterRegulation đã gặp phải và cách họ giải quyết chúng.
Thử thách 1: Trích xuất PDF tự động để xử lý tài liệu
Các văn bản pháp lý thường rất rắc rối:
- Bố cục nhiều cột
- Tiêu đề/chân trang trên mỗi trang
- Số trang được nhúng giữa câu
- Bảng biểu và chú thích
Giải pháp của chúng tôi: Chiến lược của Unstructured.io hi_resvới việc lọc các phần tử để xử lý tài liệu một cách hiệu quả.
Kết quả:
- Chất lượng trích xuất đạt 94% (so với 75% khi sử dụng thư viện PDF tiêu chuẩn)
- Tiết kiệm 30% chi phí token nhờ lọc bỏ các hiện vật.
- Văn bản sạch, có cấu trúc mà AI có thể phân tích chính xác.
Cách thực hiện chính: chỉ bao gồm các phần tử <head> Title, <footer> NarrativeTextvà <p> ListItem. Bỏ qua tiêu đề, chân trang và số trang.
Thử thách 2: Giới hạn token với tài liệu dung lượng lớn
Một số tài liệu có hơn 350 trang, vượt quá giới hạn 128K của cửa sổ ngữ cảnh GPT-4o-mini.
Giải pháp của chúng tôi: chiến lược giảm hiệu suất một cách khéo léo.
- Tính toán số lượng token ước tính trước khi gửi (1 token ≈ 4 ký tự)
- Nếu >120.000 từ: chỉ trích xuất tiêu đề và tiêu đề phụ của các phần.
- Thêm trường quản trị cho các tệp PDF được nén thủ công trong các trường hợp đặc biệt.
Sự đánh đổi: độ chính xác thấp hơn một chút đối với các tài liệu khổng lồ (90% so với 95%), nhưng tránh được tình trạng thất bại hoàn toàn.
Thử thách 3: Đối sánh phân loại ngữ nghĩa
Vấn đề: tài liệu ghi là “các hoạt động cho vay tiêu dùng”. Thuật ngữ trong phân loại là “Các tổ chức cho vay và tuyển dụng tín dụng tiêu dùng”. Phương pháp đối sánh từ khóa truyền thống không thành công.
Giải pháp của chúng tôi: tận dụng khả năng hiểu ngữ nghĩa của LLM.
- Trí tuệ nhân tạo (AI) hiểu rằng "cho vay tiêu dùng" = "Tín dụng tiêu dùng".
- Nhận biết các từ viết tắt (FCA = Financial Conduct Authority - Cơ quan Quản lý Tài chính)
- Sử dụng ngữ cảnh để làm rõ nghĩa (ICO = cơ quan quản lý dữ liệu, không phải tiền điện tử)
Lý do phương pháp đối sánh dựa trên tên hoạt động hiệu quả: Trí tuệ nhân tạo ( AI) trả về các tên thuật ngữ như ["Consumer Credit", "Data Protection"], sau đó hệ thống sẽ ánh xạ chúng đến các ID thuật ngữ (ví dụ: [35, 42]) thông qua tra cứu phân loại. Cách tiếp cận này kết hợp khả năng hiểu ngữ nghĩa của AI với các tham chiếu thực thể chính xác — AI có thể đối sánh các khái niệm về mặt ngữ nghĩa, trong khi hệ thống đảm bảo độ chính xác bằng cách tìm các thuật ngữ khớp chính xác trong từ vựng phân loại.
Xem thêm: Cách chúng tôi cải thiện độ chính xác của chatbot RAG lên 40% bằng cách chấm điểm tài liệu →
Làm thế nào để đảm bảo độ tin cậy trong quá trình sản xuất xử lý tài liệu bằng AI?
Việc chuyển từ giai đoạn chứng minh tính khả thi sang sản xuất đòi hỏi khả năng xử lý lỗi và giám sát mạnh mẽ. BetterRegulation đã xây dựng các biện pháp bảo vệ toàn diện để đảm bảo hệ thống hoạt động ổn định trong điều kiện thực tế.
Bạn xử lý lỗi trong quá trình xử lý tài liệu bằng AI như thế nào?
Ghi nhật ký toàn diện: mọi bước đều được ghi lại vào hệ thống Watchdog của Drupal—từ tải lên PDF đến phản hồi của AI. Cần thiết cho việc gỡ lỗi và giám sát.
Logic thử lại: Các lỗi API tạm thời (giới hạn tốc độ, hết thời gian chờ) sẽ kích hoạt chế độ thử lại tự động với độ trễ lũy thừa (2 giây, 4 giây, 8 giây).
Xử lý lỗi một cách nhẹ nhàng: nếu quá trình xử lý thất bại, tài liệu vẫn có thể chỉnh sửa được với các thông báo lỗi rõ ràng. Người chỉnh sửa có thể thử lại hoặc điền thông tin vào các trường theo cách thủ công.
Bảng điều khiển giám sát
Giao diện quản trị tùy chỉnh tại /admin/content/ai-processingtrack:
- Tỷ lệ thành công/thất bại
- Thời gian xử lý
- Chi phí API
- Tần suất sửa lỗi của biên tập viên (chỉ số độ chính xác)
Đánh giá hàng tuần: Nhóm của BetterRegulation kiểm tra bảng điều khiển hàng tuần để phát hiện sớm các vấn đề và tinh chỉnh các lời nhắc dựa trên các mẫu lỗi.
Tối ưu hóa hiệu suất và chi phí cho xử lý tài liệu bằng AI
Chi phí API AI có thể nhanh chóng tăng vọt nếu không được tối ưu hóa đúng cách. BetterRegulation đã triển khai một số chiến lược để giảm thiểu chi phí xử lý tài liệu trong khi vẫn duy trì hiệu suất và trải nghiệm người dùng.
Xử lý nền với độ trễ 15 phút
Vấn đề là: người biên tập thường lưu tài liệu nhiều lần liên tiếp trong quá trình chỉnh sửa. Việc kích hoạt quá trình tạo tóm tắt bằng AI tốn kém mỗi khi lưu sẽ lãng phí tiền bạc.
Giải pháp của chúng tôi: tạo bản tóm tắt và gửi đến RabbitMQ với độ trễ 15 phút.
- Người biên tập lưu tài liệu → đang chờ xử lý trong 15 phút
- Nếu người chỉnh sửa lưu lại trong vòng 15 phút → độ trễ sẽ được đặt lại.
- Sau 15 phút không có thay đổi → bản tóm tắt được tạo một lần
Tác động: Loại bỏ 60-70% các cuộc gọi API dư thừa trong các phiên chỉnh sửa nhanh. Để biết thêm các chiến lược giảm chi phí API AI, hãy xem cách định tuyến thông minh giúp giảm chi phí API AI đến 95% .
Bộ nhớ đệm giúp giảm chi phí xử lý tài liệu bằng AI như thế nào?
Văn bản PDF được trích xuất sẽ được lưu vào bộ nhớ đệm trong 7 ngày. Nếu cần tinh chỉnh yêu cầu, quá trình xử lý lại sẽ sử dụng văn bản đã lưu trong bộ nhớ đệm thay vì trích xuất lại từ PDF.
Tiết kiệm: ~0,05 bảng Anh cho mỗi lần xử lý lại (đã loại bỏ cuộc gọi đến Unstructured.io).
Xem thêm: Cách tăng tốc độ phản hồi của chatbot AI bằng bộ nhớ đệm thông minh →
Chi phí xử lý tài liệu bằng AI là bao nhiêu?
Số lượng xử lý hàng tháng (200 tài liệu):
- API GPT-4o-mini: ~42 bảng Anh/tháng (~0,21 bảng Anh/tài liệu)
- Unstructured.io: 0 bảng Anh (tự lưu trữ)
- Tổng cộng: 42 bảng Anh/tháng
Tiết kiệm chi phí tối ưu hóa so với GPT-4:
- GPT-4 sẽ có giá khoảng: ~420 bảng Anh/tháng
- Tiết kiệm: £378/tháng (giảm 90%)
Chi phí trên mỗi đơn vị thời gian tiết kiệm được:
- Tiết kiệm 50% thời gian = tiết kiệm được 50 giờ/tháng
- 42 bảng/tháng ÷ 50 giờ = 0,84 bảng/giờ tiết kiệm được
- Chi phí biên tập viên thông thường: 15-25 bảng Anh/giờ
- ROI: Lợi nhuận gấp 18-30 lần
Bạn cần lưu tâm đến những vấn đề bảo mật nào trong quá trình xử lý tài liệu bằng trí tuệ nhân tạo?
Bảo mật dữ liệu: Các tệp PDF được gửi đến API của OpenAI. Đối với các tài liệu nhạy cảm, hãy cân nhắc:
- Các chương trình LLM tự tổ chức (Llama, Mistral thông qua Ollama)
- Thỏa thuận xử lý dữ liệu với OpenAI
- Ẩn danh văn bản (xóa thông tin nhận dạng cá nhân trước khi gửi)
Bảo mật khóa API: được lưu trữ trong hệ thống cấu hình Drupal, không phải trong mã nguồn. Chỉ quản trị viên mới có quyền truy cập.
Chúng ta đã rút ra được những bài học gì từ việc triển khai xử lý tài liệu bằng trí tuệ nhân tạo?
Sau nhiều tháng phát triển và sử dụng thực tế, nhóm của BetterRegulation đã xác định được bảy bài học quan trọng có thể mang lại lợi ích cho bất kỳ ai xây dựng các giải pháp tích hợp AI tương tự. Những hiểu biết này không chỉ dừng lại ở tài liệu kỹ thuật mà còn bao gồm những kiến thức thực tiễn quý giá.
1. Kiểm tra với tài liệu thực tế
Không nên: thử nghiệm với các tệp PDF mẫu/tổng hợp.
Nên làm: Sử dụng các tài liệu thực tế từ tên miền của bạn.
Lý do: Tài liệu kiểm thử tổng hợp thường sạch sẽ, được định dạng tốt và dễ dự đoán. Tài liệu thực tế thì lộn xộn, không nhất quán và đầy rẫy các trường hợp ngoại lệ có thể làm hỏng các lời nhắc được bạn tạo ra một cách cẩn thận.
Những phát hiện của BetterRegulation trong quá trình thử nghiệm thực tế:
- Các tệp PDF được quét với khả năng nhận dạng ký tự quang học (OCR) kém: Các tệp PDF có văn bản bị biến dạng như “Cong umer Cred it Act” gây nhầm lẫn trong việc đối sánh phân loại. Giải pháp: Thêm chuẩn hóa văn bản để xử lý các lỗi OCR.
- Tài liệu đa ngôn ngữ: Các quy định của EU kết hợp các thuật ngữ pháp lý tiếng Anh và tiếng Latinh. Ban đầu, AI không thể phân loại chính xác các tài liệu này cho đến khi các gợi ý được điều chỉnh để xử lý nội dung đa ngôn ngữ.
- Lỗi đặt tên không nhất quán: cùng một tổ chức được nhắc đến với các tên gọi “FCA,” “Financial Conduct Authority,” “the Authority,” và “the FCA” trong cùng một tài liệu. Việc đối sánh ngữ nghĩa đã xử lý được lỗi này, nhưng cần phải xác thực thêm.
- Các tài liệu đồ sộ hơn 350 trang: chỉ phát hiện ra vấn đề giới hạn số lượng từ khi thử nghiệm với các bộ tài liệu quy định thực tế. Điều này dẫn đến chiến lược dự phòng là trích xuất tiêu đề.
Trước khi ra mắt, BetterRegulation đã thử nghiệm với các tài liệu pháp lý PDF thực tế, bao gồm các ấn phẩm trong hơn 5 năm. 20 tài liệu thử nghiệm đầu tiên đã phát hiện ra nhiều vấn đề hơn so với 6 tháng phát triển với các mẫu tổng hợp.
2. Sự tham gia của con người là yếu tố thiết yếu.
Không nên: Tự động hóa hoàn toàn mà không qua xem xét.
Quy trình thực hiện: AI điền thông tin, con người xem xét và phê duyệt.
Lý do: không có hệ thống AI nào là hoàn hảo, và những lỗi trong nền tảng tuân thủ pháp lý có những hậu quả nghiêm trọng. Quan trọng hơn, lỗi của AI không phải là ngẫu nhiên—chúng thường tập trung vào những tài liệu phức tạp, mơ hồ hoặc bất thường nhất, những tài liệu cần được chú ý cẩn thận nhất.
Phương pháp có sự tham gia của con người mang lại nhiều lợi ích:
- Đảm bảo chất lượng: các biên tập viên pháp lý phát hiện lỗi của AI trước khi chúng ảnh hưởng đến người dùng cuối. Trong một nền tảng tuân thủ, việc phân loại không chính xác có thể dẫn đến việc không tìm thấy hướng dẫn quy định quan trọng khi cần thiết.
- Xây dựng lòng tin: các biên tập viên tin tưởng hệ thống vì họ thấy cách nó hoạt động và có thể sửa lỗi. Việc định vị AI như một "trợ lý" chứ không phải là người thay thế sẽ giảm bớt sự phản kháng trong tổ chức và tăng khả năng áp dụng.
- Cải tiến liên tục: các chỉnh sửa của biên tập viên giúp hé lộ các mô hình trong hành vi của AI. Bằng cách theo dõi những trường nào được sửa thường xuyên nhất, bạn có thể xác định nơi cần tinh chỉnh các lời nhắc hoặc nơi cần làm rõ các phân loại.
- Nắm bắt kiến thức chuyên môn: khi người biên tập thực hiện các chỉnh sửa, họ thường áp dụng kiến thức chuyên môn tinh tế mà không được ghi nhận trong các yêu cầu ban đầu. Những chỉnh sửa này có thể được phân tích để cải thiện hệ thống theo thời gian.
- Cân bằng hiệu quả: Trí tuệ nhân tạo (AI) đảm nhiệm các công việc tẻ nhạt, lặp đi lặp lại như đọc tài liệu và trích xuất siêu dữ liệu cơ bản. Con người tập trung vào việc xem xét, điều chỉnh các trường hợp ngoại lệ và đưa ra phán đoán trong các tình huống mơ hồ. Sự phân công lao động này hiệu quả hơn so với việc chỉ sử dụng một trong hai phương pháp.
Kết quả: tiết kiệm thời gian đáng kể trong khi vẫn duy trì chất lượng cao. Biên tập viên làm việc nhanh hơn vì AI đảm nhiệm phần lớn công việc ban đầu, và sản phẩm cuối cùng nhất quán hơn vì AI không bị mệt mỏi hay mắc lỗi khi sao chép.
3. Lặp lại các gợi ý
Không nên: chỉ viết đề bài một lần rồi bỏ qua.
Nên làm: rà soát lỗi và chỉnh sửa các câu hỏi.
Lý do: lời nhắc đầu tiên của bạn sẽ tốt nhưng chưa xuất sắc. Hành vi của AI mang tính phát sinh và thường gây bất ngờ — bạn sẽ không thể dự đoán tất cả các kiểu lỗi cho đến khi xử lý hàng trăm tài liệu thực tế.
Bài học rút ra: sự cải thiện đến từ việc phân tích những sai lầm thực tế, chứ không phải từ việc lý thuyết hóa về cải tiến. Theo dõi các chỉnh sửa, tìm ra các mẫu, tinh chỉnh các câu hỏi gợi ý.
4. Các trường hợp ngoại lệ là không thể tránh khỏi.
Đừng: cho rằng trí tuệ nhân tạo sẽ xử lý mọi việc.
Nên làm: Lập kế hoạch cho các trường hợp ngoại lệ từ trước và xây dựng các phương án dự phòng linh hoạt.
Lý do: Cho dù trí tuệ nhân tạo của bạn có tốt đến đâu, vẫn sẽ có một số tài liệu làm hỏng hệ thống. Câu hỏi không phải là "liệu có xảy ra hay không" mà là "khi nào" và "tần suất như thế nào".
Danh mục các trường hợp ngoại lệ của BetterRegulation:
- Các yếu tố phá vỡ giới hạn token: các bộ quy tắc pháp lý rất lớn vượt quá cửa sổ ngữ cảnh 128K của GPT-4o-mini. Phương án dự phòng: Chỉ trích xuất và xử lý tiêu đề và đề mục – độ chính xác thấp hơn nhưng tốt hơn là hoàn toàn thất bại.
- Những thảm họa khi quét PDF: các văn bản pháp luật cũ được quét bằng công nghệ nhận dạng ký tự quang học (OCR) kém chất lượng tạo ra văn bản bị lỗi. Giải pháp thay thế: Trường quản trị để tải lên phiên bản rút gọn được nhập thủ công hoặc đánh dấu để xử lý thủ công.
- Các tài liệu thực sự mơ hồ: một số tài liệu thuộc nhiều loại khác nhau và ngay cả các chuyên gia pháp lý cũng không đồng ý về cách phân loại chính xác. Phương án dự phòng: Trí tuệ nhân tạo đưa ra nhiều lựa chọn; người biên tập đưa ra quyết định cuối cùng.
- Thiếu siêu dữ liệu: một số tệp PDF đơn giản là không chứa thông tin cần thiết như năm, URL nguồn hoặc các trường khác. Phương án dự phòng: Trả về giá trị trống thay vì tạo giá trị ảo; người biên tập sẽ điền thủ công.
Cách tiếp cận thực tế: chấp nhận rằng một số tài liệu cần được xử lý đặc biệt. Xây dựng hệ thống giám sát để nhanh chóng xác định những trường hợp này và cung cấp cho người biên tập quy trình làm việc rõ ràng để xử lý chúng. Cố gắng đạt được tự động hóa 100% sẽ tốn nhiều thời gian phát triển hơn đáng kể mà lợi ích thu được lại không đáng kể.
5. Giám sát là rất quan trọng
Không nên: triển khai rồi quên đi.
Nên làm: Xây dựng hệ thống giám sát toàn diện ngay từ ngày đầu tiên.
Lý do: Hệ thống AI có thể xuống cấp âm thầm. Việc cập nhật mô hình, thay đổi phân loại hoặc định dạng tài liệu đang phát triển có thể làm hỏng các quy trình vốn đang hoạt động tốt. Nếu không giám sát, bạn sẽ không nhận ra cho đến khi người dùng phàn nàn.
Phương pháp giám sát của BetterRegulation theo dõi:
- Tỷ lệ thành công/thất bại: các chỉ số đánh giá tổng thể về mức độ thành công của quá trình xử lý. Sự sụt giảm đột ngột cho thấy có vấn đề với hệ thống.
- Phân bổ thời gian xử lý: theo dõi hiệu suất theo thời gian. Sự gia tăng đáng kể cho thấy API bị chậm hoặc có vấn đề về giới hạn token.
- Độ chính xác theo từng trường: theo dõi xem người biên tập sửa lỗi ở những trường nào thường xuyên nhất. Giúp phát hiện những điểm cần cải thiện trong các lời nhắc.
- Xu hướng chi phí API: theo dõi mô hình chi tiêu. Các đỉnh nhọn cho thấy các vấn đề như xử lý trùng lặp, logic trì hoãn bị lỗi hoặc tăng khối lượng đột ngột.
- Các dạng lỗi: phân loại lỗi theo loại. Mỗi dạng lỗi sẽ có các chiến lược khắc phục cụ thể.
Giá trị của việc phát hiện sớm: giám sát cung cấp cảnh báo sớm khi các dịch vụ bên ngoài thay đổi hành vi hoặc khi các mẫu xử lý tài liệu thay đổi, cho phép thích ứng nhanh chóng trước khi người dùng bị ảnh hưởng.
6. Tối ưu hóa chi phí rất quan trọng.
Không nên: mặc định sử dụng mô hình AI đắt nhất.
Nên làm: thử nghiệm các mẫu rẻ hơn trước; tối ưu hóa dựa trên chi phí thực tế.
Lý do: "Sử dụng AI tốt nhất" nghe có vẻ thông minh nhưng lại lãng phí tiền bạc. Đối với nhiều tác vụ, các mô hình rẻ hơn cũng hoạt động tốt không kém. Hành trình tối ưu hóa chi phí của BetterRegulation đã mang lại khoản tiết kiệm đáng kể so với cách tiếp cận đơn giản là sử dụng các mô hình cao cấp cho mọi thứ.
Quyết định 1: GPT-4o-mini vs GPT-4
- Giả định ban đầu: “GPT-4 tốt hơn, vậy nên hãy sử dụng GPT-4.”
- Kiểm chứng thực tế: đã thử nghiệm cả hai mô hình trên 50 tài liệu. GPT-4: độ chính xác 96%. GPT-4o-mini: độ chính xác 95%.
- Phân tích chi phí: GPT-4: 1,05 bảng Anh/tài liệu. GPT-4o-mini: 0,21 bảng Anh/tài liệu.
- Quyết định: Tăng độ chính xác 1% không đáng để tăng chi phí gấp 5 lần. Chọn GPT-4o-mini.
- Tiết kiệm hàng năm: £2.016 (200 tài liệu/tháng × 12 tháng × £0,84 tiết kiệm mỗi tài liệu)
Quyết định 2: Tự lưu trữ trên Unstructured.io
- Tùy chọn SaaS: 0,10-0,20 bảng Anh cho mỗi lần xử lý tài liệu
- Tùy chọn tự lưu trữ: chạy trên cụm Kubernetes hiện có, hoàn toàn miễn phí (chi phí tính toán ước tính khoảng 5 bảng Anh/tháng)
- Quyết định: Tự triển khai trên cơ sở hạ tầng hiện có.
- Tiết kiệm hàng năm: £240-480 (200 tài liệu/tháng × 12 tháng × £0.10-0.20)
7. Bắt đầu đơn giản, sau đó tăng dần độ phức tạp.
Đừng cố gắng xây dựng toàn bộ tầm nhìn ngay từ ngày đầu tiên.
Nên làm: ra mắt với mức AI tối thiểu khả thi, sau đó cải tiến dựa trên trải nghiệm sử dụng thực tế.
Lý do: Bạn không thể biết điều gì sẽ hiệu quả cho đến khi người dùng thực sự tương tác với dữ liệu thực. Bắt đầu với những thứ phức tạp đồng nghĩa với việc phát triển lâu hơn, nhiều lỗi hơn và lãng phí công sức vào những tính năng mà người dùng có thể không cần.
Bạn cần những công cụ và nguồn lực nào để xử lý tài liệu bằng trí tuệ nhân tạo?
Bạn đã sẵn sàng triển khai xử lý tài liệu bằng AI trong dự án Drupal của mình chưa? Dưới đây là các module, dịch vụ và tài nguyên thiết yếu bạn cần để bắt đầu.
Mô-đun Drupal
Yêu cầu:
- Mô-đun AI - khung tích hợp AI cốt lõi cho Drupal
- AI Automators - mô-đun con cung cấp công cụ quản lý quy trình làm việc cho các quy trình AI nhiều bước.
Hữu ích:
- Giao diện người dùng hàng đợi - quản lý các hàng đợi nền
- Module Unstructured - Tích hợp Drupal cho Unstructured.io
Dịch vụ bên ngoài
API AI:
- API của OpenAI - Mô hình GPT (khuyến nghị: GPT-4o-mini)
- Anthropic Claude - nhà cung cấp chương trình LLM thay thế
Xử lý PDF:
- Unstructured.io - phần mềm trích xuất PDF tốt nhất (tự lưu trữ hoặc SaaS)
- GitHub phi cấu trúc - mã nguồn mở
Cơ sở hạ tầng
Docker/Kubernetes:
- Docker Compose - phát triển cục bộ
- Kubernetes - triển khai trong môi trường sản xuất
Hàng đợi tin nhắn:
- RabbitMQ - hàng đợi tin nhắn đáng tin cậy
- API hàng đợi Drupal - hàng đợi tích hợp sẵn
Bạn đã sẵn sàng triển khai xử lý tài liệu bằng AI trong Drupal chưa?
Nghiên cứu trường hợp này dựa trên việc triển khai thực tế của chúng tôi cho BetterRegulation, nơi chúng tôi đã tích hợp AI Automators, Unstructured.io và GPT-4o-mini để tự động hóa quy trình xử lý tài liệu cho hơn 200 tài liệu pháp lý mỗi tháng với độ chính xác trên 95% và tiết kiệm thời gian 50%. Hệ thống đã hoạt động trong môi trường sản xuất nhiều tháng, mang lại kết quả ổn định và lợi tức đầu tư (ROI).
Bạn quan tâm đến việc xây dựng hệ thống xử lý tài liệu bằng AI cho trang web Drupal của mình? Nhóm của chúng tôi chuyên tạo ra các giải pháp xử lý tài liệu bằng AI chất lượng cao, cân bằng giữa độ chính xác, hiệu suất và hiệu quả chi phí. Chúng tôi đảm nhiệm mọi thứ từ thiết kế kiến trúc và kỹ thuật nhanh chóng đến triển khai và tối ưu hóa. Hãy truy cập dịch vụ phát triển AI tạo sinh của chúng tôi để khám phá cách chúng tôi có thể giúp bạn tự động hóa quá trình xử lý tài liệu và giúp nhóm biên tập của bạn tập trung vào công việc chiến lược.
