1. Định hướng
- Thời gian: chạy duy nhất lần đầu tiên
- Thường các trang trả phí vẫn cho lấy danh sách mà không cần đăng nhập. Nên bước này không cần cookies.
- Kiểm tra có khoảng bao nhiêu trang (?page=N) để chạy từ 1 đến N
- Cách 1. Cho chạy tất cả các trang lần lượt cùng lúc: nếu danh sách sắp xếp theo thứ tự thời gian giảm dần --> cũng không sợ miss bài viết. Nhưng có nguy cơ trùng bài viết --> script cần kiểm tra có bị trùng không mới ghi vào danh sách.
- Ví dụ này đang dùng cách 1. Và điều chỉnh khoảng cách giữa các lần lấy xa nhau ra.
- Cách 2. Đối với trang có N lớn, liên tục update, trang lại giới hạn query --> có thể đặt cron với mỗi khoảng N1, N2, ... Việc đặt các khoảng này đảm bảo an toàn, không bị chặn. Cũng lưu ý danh sách cần sắp xếp theo thứ tự thời gian giảm dần (mới lên trước) với lý do như cách 1.
- Cách 1. Cho chạy tất cả các trang lần lượt cùng lúc: nếu danh sách sắp xếp theo thứ tự thời gian giảm dần --> cũng không sợ miss bài viết. Nhưng có nguy cơ trùng bài viết --> script cần kiểm tra có bị trùng không mới ghi vào danh sách.
- Test cần thận
- Đưa vào cron để ổn định, dù chỉ chạy 1 lần duy nhất
2. Tiến hành
Script dưới là ví dụ cách lấy danh sách:
import requestsfrom bs4 import BeautifulSoupimport pandas as pdimport reimport timeimport randomimport tracebackfrom datetime import datetimeimport os
# ================== CẤU HÌNH ==================SCRIPT_DIR = os.path.dirname(os.path.abspath(__file__))LOG_FILE = os.path.join(SCRIPT_DIR, "1-1-LayDanhSach.log")OUTPUT_FILE = os.path.join(SCRIPT_DIR, "1-1-LayDanhSach.csv")
# URL mẫu, bắt buộc có {page} để format số trangTARGET_URL = ("https://domainwebiste.com/path/to/danh-sach?page={page}")
# Tổng số trang cần crawlTOTAL_PAGE = 18600
# Độ trễ giữa các trang (giây) để tránh captcha / lockDELAY_NEXT = (3.0, 7.5) # có thể để 1 số float hoặc (min, max)# ==============================================
HEADER_COLUMNS = ["tt", "tieude", "ngaybanhanh", "capnhat", "url", "uuid", "LanDau", "NgayKiemTraTrungLap"]
def _sleep_delay(): if isinstance(DELAY_NEXT, (list, tuple)) and len(DELAY_NEXT) == 2: t = random.uniform(float(DELAY_NEXT[0]), float(DELAY_NEXT[1])) else: t = float(DELAY_NEXT) time.sleep(t)
def now_str(): return datetime.now().strftime("%Y-%m-%d %H:%M:%S")
def log(message: str): timestamp = now_str() line = f"[{timestamp}] {message}" os.makedirs(os.path.dirname(LOG_FILE), exist_ok=True) with open(LOG_FILE, "a", encoding="utf-8") as log_file: log_file.write(line + "\n") print(line)
def ensure_csv_initialized(): """Tạo file CSV nếu chưa có. Nếu đã có, đảm bảo đủ các cột (nâng cấp cột mới nếu thiếu).""" if not os.path.exists(OUTPUT_FILE) or os.path.getsize(OUTPUT_FILE) == 0: # tạo file mới với header pd.DataFrame(columns=HEADER_COLUMNS).to_csv(OUTPUT_FILE, index=False, encoding="utf-8-sig") return
# Nâng cấp cột nếu thiếu try: df = pd.read_csv(OUTPUT_FILE, dtype=str, encoding="utf-8-sig") except Exception as e: log(f"❌ Không đọc được {OUTPUT_FILE}: {e}") raise
changed = False for col in HEADER_COLUMNS: if col not in df.columns: df[col] = "" # thêm cột mới, để trống changed = True
# Giữ đúng thứ tự cột if list(df.columns) != HEADER_COLUMNS: df = df.reindex(columns=HEADER_COLUMNS) changed = True
if changed: df.to_csv(OUTPUT_FILE, index=False, encoding="utf-8-sig")
def load_state(): """Tải map uuid->index và tt_max hiện có.""" df = pd.read_csv(OUTPUT_FILE, dtype=str, encoding="utf-8-sig") df = df.fillna("") uuid_to_idx = {} for idx, u in enumerate(df["uuid"].astype(str)): uuid_to_idx[u.strip()] = idx # tt_max: lấy số lớn nhất trong cột tt (nếu rỗng thì 0) try: tt_vals = pd.to_numeric(df["tt"], errors="coerce") tt_max = int(tt_vals.max()) if not tt_vals.isna().all() else 0 except Exception: tt_max = 0 return df, uuid_to_idx, tt_max
def append_new_row(row_dict, tt_next: int): """Ghi ngay 1 dòng mới vào CSV (append).""" r = { "tt": tt_next, "tieude": row_dict.get("tieude", ""), "ngaybanhanh": row_dict.get("ngaybanhanh", ""), "capnhat": row_dict.get("capnhat", ""), "url": row_dict.get("url", ""), "uuid": row_dict.get("uuid", ""), "LanDau": now_str(), "NgayKiemTraTrungLap": "" } df_row = pd.DataFrame([r], columns=HEADER_COLUMNS) df_row.to_csv(OUTPUT_FILE, mode="a", index=False, header=False, encoding="utf-8-sig")
def update_duplicate_timestamp(df, uuid_to_idx, uuid_val: str): """Cập nhật cột NgayKiemTraTrungLap cho uuid đã tồn tại và ghi lại toàn bộ file.""" idx = uuid_to_idx.get(uuid_val, None) if idx is None: return False current = str(df.at[idx, "NgayKiemTraTrungLap"]) if "NgayKiemTraTrungLap" in df.columns else "" ts = now_str() df.at[idx, "NgayKiemTraTrungLap"] = (current + ", " + ts).strip(", ").strip() # Ghi lại toàn bộ file ngay lập tức df.to_csv(OUTPUT_FILE, index=False, encoding="utf-8-sig") return True
def parse_page(html: bytes) -> list: soup = BeautifulSoup(html, "html.parser") entries = soup.find_all("div", class_=re.compile(r"content-\d+")) rows = [] for entry in entries: title_tag = entry.select_one("div.left-col div.nq p.nqTitle a") tieude = title_tag.text.strip() if title_tag else "" url = title_tag["href"].strip() if title_tag and title_tag.has_attr("href") else ""
match = re.search(r"-(\d+)\.aspx", url) uuid = match.group(1) if match else ""
ngaybanhanh_tag = entry.select_one("div.right-col p:nth-of-type(1)") ngaybanhanh = (ngaybanhanh_tag.text or "").replace("Ban hành:", "").strip() if ngaybanhanh_tag else ""
capnhat_tag = entry.select_one("div.right-col p:nth-of-type(4)") capnhat = (capnhat_tag.text or "").replace("Cập nhật:", "").strip() if capnhat_tag else ""
rows.append({ "tieude": tieude, "ngaybanhanh": ngaybanhanh, "capnhat": capnhat, "url": url, "uuid": uuid }) return rows
def crawl_page(page_num: int, max_retry: int = 3) -> list: url = TARGET_URL.format(page=page_num) headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)", "Accept-Language": "vi-VN,vi;q=0.9,en-US;q=0.8,en;q=0.7", "Connection": "close", }
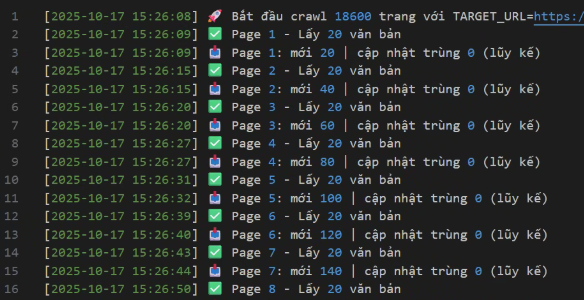
for attempt in range(1, max_retry + 1): try: with requests.Session() as s: s.headers.update(headers) response = s.get(url, timeout=15) if response.status_code != 200: log(f"❌ Page {page_num} - HTTP {response.status_code}") return [] rows = parse_page(response.content) if not rows: log(f"⚠️ Page {page_num} - Không có văn bản") else: log(f"✅ Page {page_num} - Lấy {len(rows)} văn bản") return rows
except Exception as e: log(f"⚠️ Page {page_num} - Thử lần {attempt} lỗi: {e}") time.sleep(3)
log(f"❌ Page {page_num} - Lỗi sau {max_retry} lần thử") traceback.print_exc() return []
def crawl_all(n_pages: int): start_time = datetime.now() log(f"🚀 Bắt đầu crawl {n_pages} trang với TARGET_URL={TARGET_URL}")
ensure_csv_initialized() df, uuid_to_idx, tt_max = load_state() total_new = 0 total_dup_updates = 0
for i in range(1, n_pages + 1): rows = crawl_page(i) if not rows: _sleep_delay() continue
# Duyệt từng dòng và "chốt" vào file ngay for r in rows: u = (r.get("uuid") or "").strip() if not u: # bỏ qua item không có uuid continue
if u in uuid_to_idx: # Cập nhật timestamp trùng lặp ok = update_duplicate_timestamp(df, uuid_to_idx, u) if ok: total_dup_updates += 1 else: log(f"⚠️ Không cập nhật được timestamp cho uuid={u}") else: # Thêm mới tt_max += 1 append_new_row(r, tt_max) # Đồng bộ vào df & map (để lần sau cập nhật nhanh) new_row = { "tt": str(tt_max), "tieude": r.get("tieude", ""), "ngaybanhanh": r.get("ngaybanhanh", ""), "capnhat": r.get("capnhat", ""), "url": r.get("url", ""), "uuid": u, "LanDau": now_str(), # sẽ không khớp chính xác giây với file (do append_new_row) nhưng đủ mục tiêu "NgayKiemTraTrungLap": "" } # Thêm vào df (trong bộ nhớ) để những lần sau cập nhật nhanh df = pd.concat([df, pd.DataFrame([new_row], columns=HEADER_COLUMNS)], ignore_index=True) uuid_to_idx[u] = len(df) - 1 total_new += 1
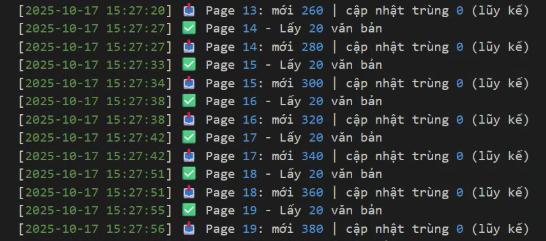
log(f"📥 Page {i}: mới {total_new} | cập nhật trùng {total_dup_updates} (lũy kế)") _sleep_delay()
log(f"✅ Hoàn thành. Thêm mới: {total_new} | Cập nhật trùng: {total_dup_updates}") log(f"⏱️ Từ: {start_time} → {datetime.now()}")
if __name__ == "__main__": crawl_all(n_pages=TOTAL_PAGE)
3. Đưa vào cron
Test:
python 1-1-LayDanhSach.py
Crontab:
sudo nano /etc/crontab
Thêm dòng sau để test cron đã chạy hay chưa:
13 15 * * * root mkdir /mnt/e/FolderTest/testcron
Chờ xem có folder testcron được tạo ra chưa. Nếu thành công sẽ thấy folder này, như hình dưới:
Nếu cron đã chạy đúng có thể bắt đầu thêm task chạy scrip python
Xác định đường dẫn tuyệt đối đén Python trong myenv:
which python
Kết quả mong đợi:
/mnt/e/Project/myenv/bin/python
Thêm task vào crontab
26 15 17 10 * root /mnt/e/Project/myenv/bin/python /mnt/e/Project/1-1-LayDanhSach.py >> /mnt/e/Project/1-1-LayDanhSach-CRONTAB.log 2>&1
Kiểm tra cron có chạy hay không bằng cách xem các log file và file dữ liệu lấy về:

Các trang phức tạp, có thể cần lưu ý cải thiện:
- Tăng DELAY_NEXT để không bị captcha, bị chặn
- Thêm lệnh ngưng khi thấy Captcha hoặc lỗi và thông báo cụ thể
- Việc dùng Linux và Headless browser để crawl có nhiều rủi ro nếu như website chống bot mạnh. Việc chuyển qua Windows khắc phục được triệt để. Khi đó sẽ mở trình duyệt thật, chúng ta có thể vào xác nhận human.
- Đăng nhập để gửi ý kiến
